
Dans cet article, nous décrirons un moyen de sauvegarder des données à l’aide de l’outil Rsync. Précision importante : nous n’aborderons pas l’usage avec un service rsync résident ( mode "daemon"). Nos données sont en quantité importante et notre sauvegarde sera journalière.
Présentation rapide de Rsync
Rsync est un outil de sauvegarde qui a la particularité de supporter un grand nombre d’options. Il est utilisé en ligne de commande ou au travers de scripts automatisés. La sauvegarde peut être déportée à travers un réseau. Rsync utilisera par exemple le canal ssh, un transfert crypté et une compression des données avant envoi.
Comme son nom l’indique, il procède par synchronisation, c’est-à-dire qu’il compare le contenu à sauvegarder de la sauvegarde précédente et ne transmet ainsi que la différence. Allié à la compression des données, c’est donc l’outil redoutable pour les sauvegardes de type NAS. Pour une sauvegarde d’un ordinateur à un autre, il est possible d’initier la sauvegarde à partir de la source ou bien à partir de la destination.
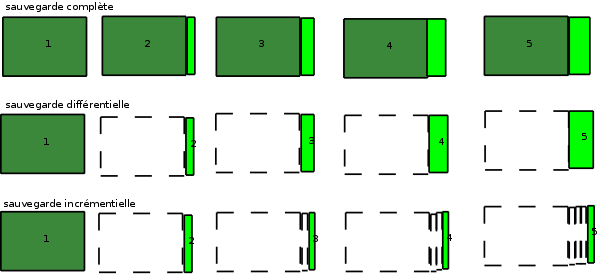
La sauvegarde incrémentielle
la synchronisation consiste à maintenir un « miroir » des données à sauvegarder. En d’autres termes, on stocke à l’identique. L’inconvénient majeur de ce type de sauvegarde est l’absence d’historique : si vous écrasez un fichier A par un fichier B puis que vous effectuez la sauvegarde, vous ne pourrez plus récupérer le fichier A puisque la sauvegarde aura mis à jour de la même manière les données sauvegardées (donc là aussi A sera écrasé par B).
La solution est de maintenir un historique des sauvegardes. Par exemple, vous sauvegardez chaque mois dans un dossier différent. Nous sommes début juillet et vous vous rendez compte que vous avez supprimé votre fichier fin juin par erreur. Inutile de regarder la sauvegarde du 1er juillet : il était déjà supprimé. C’est donc la sauvegarde mensuelle du 1er juin qu’il faudra fouiller pour retrouver votre fichier.
Evidemment, dans cet exemple, si vous avez créé le fichier le 2 juin et que vous l’avez supprimé le 27 juin, ce n’est pas récupérable ! D’où l’importance de concilier la fréquence des sauvegardes et la taille occupée par les sauvegardes.
La sauvegarde incrémentielle consiste à ne sauvegarder que la différence par rapport à la précédente sauvegarde. On stocke les fichiers nouvellement créés, les fichiers ayant subi une modification et la liste des fichiers supprimés. De cette manière, on réduit fortement l’espace occupé : dans le système précédent , un fichier était répété dans chaque sauvegarde.
Le traitement "batch"
Rsync dans son fonctionnement classique fonctionne ainsi :
rsync -options « source » « destination »
Parmi les options, nous allons nous intéresser à deux options :
— write-batch
— write-batch-only
La première effectue la synchronisation mais conserve également les différences dans un fichier. La seconde simule la synchronisation et conserve les différences dans un fichier.
Répétons-le : rsync fonctionne par comparaison. il faut donc effectuer une sauvegarde entre les données à sauvegarder et la sauvegarde précédente. C’est le rôle de la sauvegarde au jour-le-jour dans le diagramme ci-dessous :
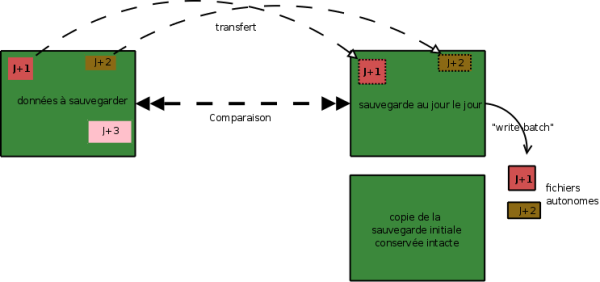
Le traitement write-batch vient apporter EN PLUS de la sauvegarde « au-jour-le-jour » un fichier autonome (J+1, J+2...) comprenant tout ce qui a changé.
La récupération des données
Si sur le schéma ci-dessus, on veut récupérer nos données à J+1, on ne peut pas repartir de notre sauvegarde « au-jour-le-jour » : elle intègre les données J+2. on ne peut pas non plus appliquer le batch J+1 sur les données actuelles car il y a J+2 et J+3... Par ailleurs, les fichiers autonomes obtenus par batchs ne sont pas réversibles : ils contiennent le contenu des nouveaux fichiers, le contenu des fichiers modifiés mais pas le contenu avant modification. ils contiennent la liste des fichiers supprimés mais pas leur contenu.
C’est la raison pour laquelle nous avons conservé une sauvegarde initiale. C’est un point de départ. On pourra, partant de cette base, appliquer les fichiers autonomes batchs que l’on souhaite et ainsi retrouver la situation de nos données au jour souhaité. Si on veut les données à J+1, on applique le fichier batch "J+1 alors que si on veut retrouver la situation à J+2 , on appliquera successivement et dans cet ordre les fichiers autonomes batchs J+1 et J+2.
rsync —read-batch « nom_du_batch » « destination » aura cette fonction.
Pour aller plus loin
Evidemment, rsync comporte un nombre d’options incroyable que vous pourrez découvrir et exploiter notamment en lisant la manpage [1].
Vous y apprendrez à effectuer des sauvegardes à travers un réseau, en cryptant, en compressant vos données. Tout cela est bien expliqué et la documentation que l’on trouve sur internet et souvent complète. Je trouvais, par contre, que l’usage du mode "batch" n’était pas suffisamment expliqué et que l’on pouvait ainsi passer à côté de solutions pratiques et souples.
L’exemple de cet article
Dans cet article, nous avons un serveur Windows2000, contrôleur de domaine et serveur de fichier. On fait le choix de ne rien installer sur le serveur pour ne pas affaiblir sa fiabilité. Les données sur ce serveur sont accessibles au travers d’un partage Microsoft. Sur notre serveur de sauvegarde, outre rsync, il devra y avoir SAMBA (le client) pour accéder au partage. Dans cet article, on considère que vous avez effectué ce partage sur le serveur où qu’il existait déjà et que la connexion au partage est également faite dans le dossier /mnt/mes_donnees (si vous ne savez pas le faire, Linux fournit des utilitaires très simples d’emploi comme draksambashare [2] sous Mandriva Linux)
En appliquant les indications ci-dessus, vous pourriez avoir un script de sauvegarde lancé chaque nuit par crontab qui aurait cette forme (avec commentaires précédés de #) :
#!/bin/bash
log="/var/log/rsync/rsync.log"
path="/data/"
jourlejour="fildeleau"
laveille=<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZSArJWQgLS1kYXRlPSctMWRheSc8L2NvZGU+"></span>
lemois=<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZSArJW08L2NvZGU+"></span> # numéro du mois 01..12
lemoisdernier=<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZSArJW0gLS1kYXRlPSctMW1vbnRoJzwvY29kZT4="></span>
numerojour=<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZSArJWQ8L2NvZGU+"></span>
# accès au serveur
#mount /mnt/mes_donnees
# création du dossier s'il n'existe pas
if [[ ! ( -e $path$lemois ) ]];
then mkdir $path$lemois
fi
#décommentez la ligne ci-dessous pour passer en différentielle
#if [[ ! ( -e $path$lemois ) ]] then mkdir $path$lemois"/diff/"
echo "debut de la sauvegarde "<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZTwvY29kZT4="></span> >> $log
if [[ $numerojour == "01" ]];
then
echo "création de la sauvegarde initiale en début de mois" >> $log
cp -R $path$lemoisdernier/* $path$lemois/
#on démarre de la sauvegarde du mois précédent pour réduire la charge réseau
echo " sauvegarde du jour "<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZTwvY29kZT4="></span> >> $log
# en différentielle décommentez la ligne ci-dessous
#rsync -av --read-batch=$path/diff/$laveille ${1:-$path/$lemois} 2>&1 >> $log
#accès au serveur pour mise à jour
sudo mount /mnt/mes_donnees
rsync -av /mnt/mes_donnees $path$lemois 2>&1 >> $log
sudo umount /mnt/mes_donnees
#plus besoin d'accès au serveur, on met à niveau la sauvegarde au jour le jour
# en différentielle commentez la ligne ci-dessous
rsync -av $path$lemois /$path$jourlejour
else
#accès au serveur
sudo mount /mnt/mes_donnees
# lancement de la sauvegarde journalière via SAMBA (charge réseau)
echo "1) sauvegarde batchée "<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZTwvY29kZT4="></span> >> $log
rsync -av --write-batch=$path$lemois"/diff/"$numerojour /mnt/mes_donnees $path$jourlejour 2>&1 >> $log
#différentielle, commentez la ligne du-dessus et décommentez celle du dessous
#rsync -av --write-batch=$path"/diff/"$numerojour /mnt/mes_donnees $path$lemois 2>&1 >> $log
#plus besoin du serveur
sudo umount /mnt/mes_donnees
fi
echo "fin de sauvegarde du "<span class="base64" title="PGNvZGUgY2xhc3M9J3NwaXBfY29kZSBzcGlwX2NvZGVfaW5saW5lJyBkaXI9J2x0cic+ZGF0ZTwvY29kZT4="></span> >> $logOn aura donc dans le dossier "/data" :
– plusieurs sous-dossiers comportant la sauvegarde initiale (janvier, février, mars...)
– chaque mois comprenant lui-même un sous-dossier "diff" contenant les fichiers autonomes "batchs" numérotés par le jour du mois de 1 à 31...
– un sous-dossier "fildeleau" contenant la copie des données de la veille (sauvegarde au-jour-le-jour)
on pourra donc rétablir nos données à n’importe quelle date (pourvu que vous ayez suffisamment de taille de stockage)
Si on passe en mode différentielle, on aura dans le dossier "/data" :
– plusieurs sous-dossiers comportant la sauvegarde initiale (janvier, février...) dont on conservera idéalement les 3 derniers mois seulement
– un unique sous-dossier diff contenant les fichiers autonomes batchés numérotés de 1 à 31
On pourra dans ce cas remonter jusque 30 jours en arrière mais l’occupation d’espace de stockage sera bien moins important (on n’a plus besoin de la sauvegarde au-jour-le-jour) et la restauration des données beaucoup plus rapide (pour rétablir la situation au 15 juin, il suffira d’appliquer le batch 15 au dossier /data/juin avant le 16 juillet).
conclusion
Cet article n’a pas pour but de vous fournir une solution clefs-en-main mais de vous faire découvrir une utilisation possible de rsync pour répondre aux besoins de sauvegardes différentielles ou incrémentielles. Pour adapter cette expérience à votre propre besoin, il faut tenir compte de plusieurs paramêtres :
– l’espace de stockage disponible
– la variabilité des données à stocker
– la profondeur nécessaire (combien de sauvegardes en arrière doit-on disposer ?)
– la fréquence (journalière, hebdomadaire, mensuelle...)
qui vous amèneront à privilégier l’une ou l’autre des solutions.